
In this update we try to address three key questions:
💰 How has inference cost developed and where is it today?
🪧 Where is inference cost going next?
🪙 What does it mean for investors?
Inference Cost is Rising, not Falling
In the ecosystem of large language models, GPU plays a dual role: training and inference.
Over the first 16 months after the launch of Gpt-3.5, the market’s attention was fixated on training costs, often making headlines for their staggering scale. However, following the wave of API price cuts in mid-2024, the spotlight has shifted to inference costs—revealing that while training is expensive, inference, even more.
According to Barclays, training the GPT-4 series required approximately $150 million in compute resources. Yet, by the end of 2024, GPT-4’s cumulative inference costs are projected to reach $2.3 billion—15x the cost of training.
On a broader scale, demand for inference computers is expected to grow 118-fold by 2026, reaching 3x the total demand for training.
The September 2024 release of GPT-o1 further accelerated compute demand to shift from training towards inference. GPT-o1 generates 50% more tokens per prompt compared to GPT-4o and its enhanced reasoning capabilities result in the generation of inference tokens at 4x output tokens of GPT-4o.
Tokens, the smallest units of textual data processed by models, are central to inference compute. Typically, one word corresponds to about 1.4 tokens. Each token interacts with every parameter in a model, requiring two floating-point operations (FLOPs) per token-parameter pair. Inference compute can be summarized as:
Total FLOPs ≈ Number of Tokens × Model Parameters × 2 FLOPs.
Compounding this volume expansion, the price per token for GPT o1 is 6x that for GPT-4o’s, resulting in a 30-fold increase in total API costs to perform the same task with the new model. Research from Arizona State University shows that, in practical applications, this cost can soar to as much as 70x. Understandably, GPT-o1 has been available only to paid subscribers, with usage capped at 50 prompts per week.

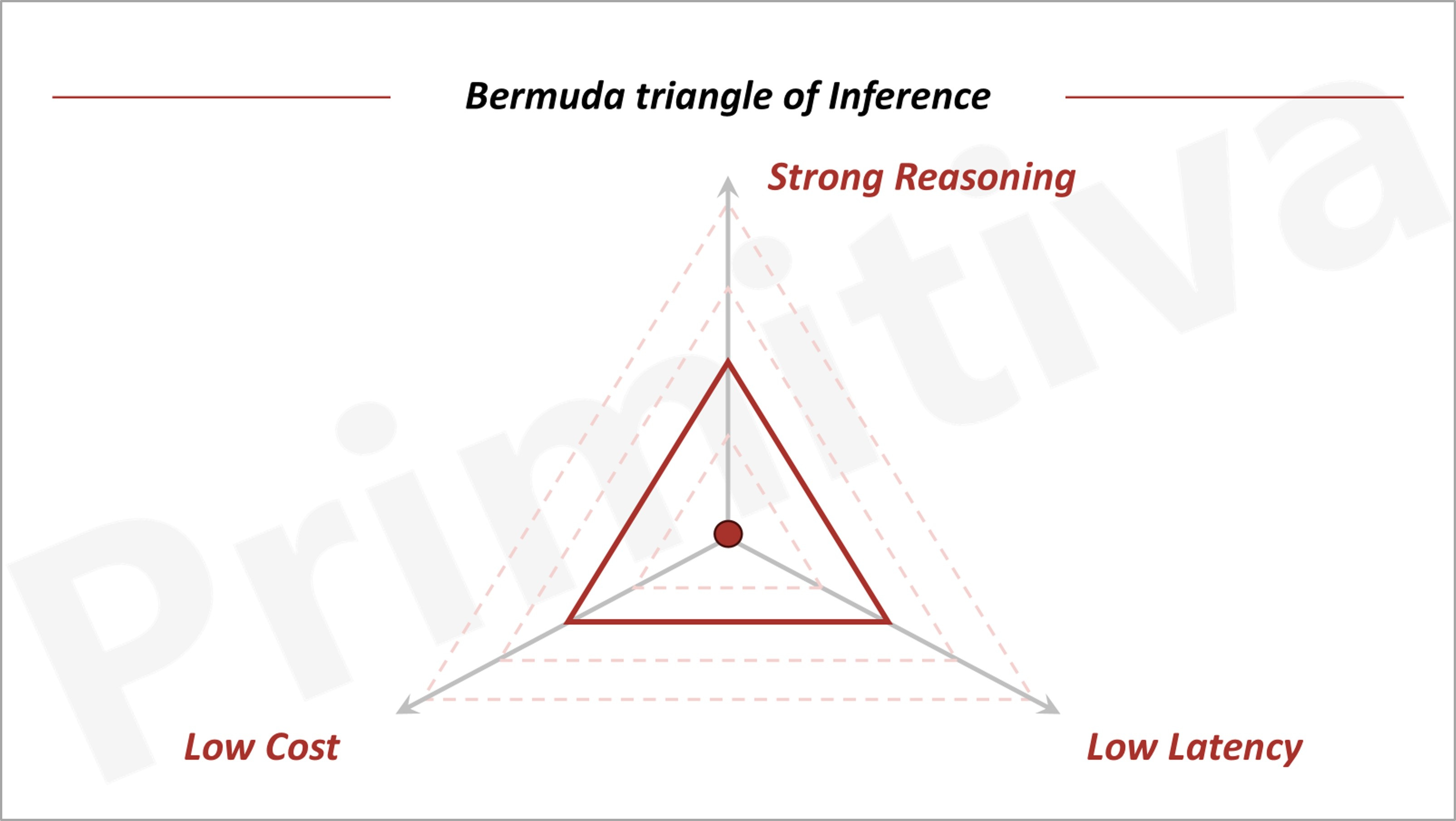
The cost surge of GPT-o1 highlights the trade-off between compute costs and model capabilities, as theorized by the Bermuda Triangle of GenAI: everything else equal, it is impossible to make simultaneous improvements on inference costs, model performance, and latency; improvement in one will necessarily come at sacrifice of another.
However, advancements in models, systems, and hardware can expand this "triangle," enabling applications to lower costs, enhance capabilities, or reduce latency. Consequently, the pace of these cost reductions will ultimately dictate the speed of value creation in GenAI.
Every Technological Revolution Confronts the Cost Challenge
Historically, every productivity revolution driven by technology has faced the challenge of high costs before achieving mass adoption.
James Watt’s steam engine was such an example. It was invented in 1776, but took 30 years of innovations, such as the double-acting design and centrifugal governor, to raise thermal efficiency from 2% to 10%—making steam engines a viable power source for factories. Similarly, while the ring-armature electric motor (1871) enabled stable direct current output, only later advances in multiphase motors and transformers made electricity economical for widespread use.
For GenAI, inference costs are the equivalent barrier. Unlike pre-generative AI software products that were regarded as a superior business model than "traditional businesses" largely because of its near-zero marginal cost, GenAI applications need to pay for GPUs for real-time compute. While SaaS companies spend only 5% of their revenue on server expenses, GenAI applications face far higher costs, often exceeding half of total revenue.
For example, GPT-4 incurred $2.3 billion in inference costs between its launch in March 2023 and the end of 2024, accounting for 49% of its total revenue.

High inference costs significantly compress the profit margins of GenAI applications, making operation and scalability particularly challenging.
For SaaS startups, marketing, promotion, and customer acquisition typically consume around 30% of annual revenue. If GenAI applications were to allocate a similar proportion to sales and marketing, the combined costs of inference and these expenses would often match or exceed total annual revenue—leaving minimal resources for other operational needs.
This creates substantial barriers to scalability, with success typically limited to two types of applications: those with exceptional fundraising capabilities to sustain cash-burning models or those with highly efficient distribution strategies that enable rapid growth under constrained budgets. There is a third possibility, which is if the product is 10x better to command a much higher price than its SaaS counterparts, while maintaining a significant moat to sustain pricing power.
Many GenAI applications remain uncommercialized due to these prohibitive costs. For instance, OpenAI’s Sora and Meta’s recently launched Movie Gen video generation tool incur $20 in inference costs for a single minute of video—assuming only one in five outputs meets quality standards. As a result, such tools remain inaccessible to the public, while most video applications today focus on ultra-short clips of just 2–6 seconds.
AI agents, another hot topic in GenAI, face similar hurdles. Each interaction involves multiple model calls, driving hourly costs for real-time agents as high as $1 per user.
These estimates already factor in the use of more economical GPU cloud services. Deploying models via APIs would inflate costs further, by as much as 2–5x, compounding the financial challenges faced by GenAI applications.

Model and System Innovations Have Driven Down Inference Costs
Inference costs have sharply declined over the past two years. Since its release in March 2023, GPT-3.5 Turbo has seen a 70% price reduction within just seven months. Similarly, Google’s Gemini 1.5 Pro, updated in October 2024, has undergone a price cut of over 50% compared to its initial launch in May.
Meanwhile, GPT-4o mini, launched in late July, demonstrates significantly superior reasoning capabilities—scoring 40% higher on the Artificial Analysis Quality Index (AAQI), a comprehensive model quality metric. Yet, its price is just 10% of GPT-3.5 Turbo’s original launch cost. Within a year, the cost of accessing a more powerful model has dropped to one-tenth, highlighting an extraordinary pace of cost reduction.

Assuming a 90% reduction in GPU costs for model inference and API prices, approximately 20% of this decrease can be attributed to lower GPU cloud server costs, while the remaining 70% is driven by improvements in inference efficiency.
Two key strategies are central to enhancing inference efficiency:
Reducing Inference Compute: Lowering model parameters directly reduces computational demands. In 2024, OpenAI, Google, and Meta introduced smaller models that achieved this goal. Techniques, like Mixture of Experts (MoE), further optimize parameter usage, balancing computational load with model performance—examples include GPT and Mistral. Similarly, low-precision methods, such as FP16 and FP8, significantly reduce compute requirements while improving Model FLOPS Utilization (MFU).
Increasing Model FLOPS Utilization (MFU): GPU computations involve two primary actions: data loading and processing. During inference, slower data transmission often leads to compute wastage. To address this, advancements have been made both at the model layer (e.g., attention mechanisms like GQA and sparsification methods such as Sliding Window Attention) and the system layer (e.g., inference engines like Flash Attention and batching techniques like Continuous Batching).
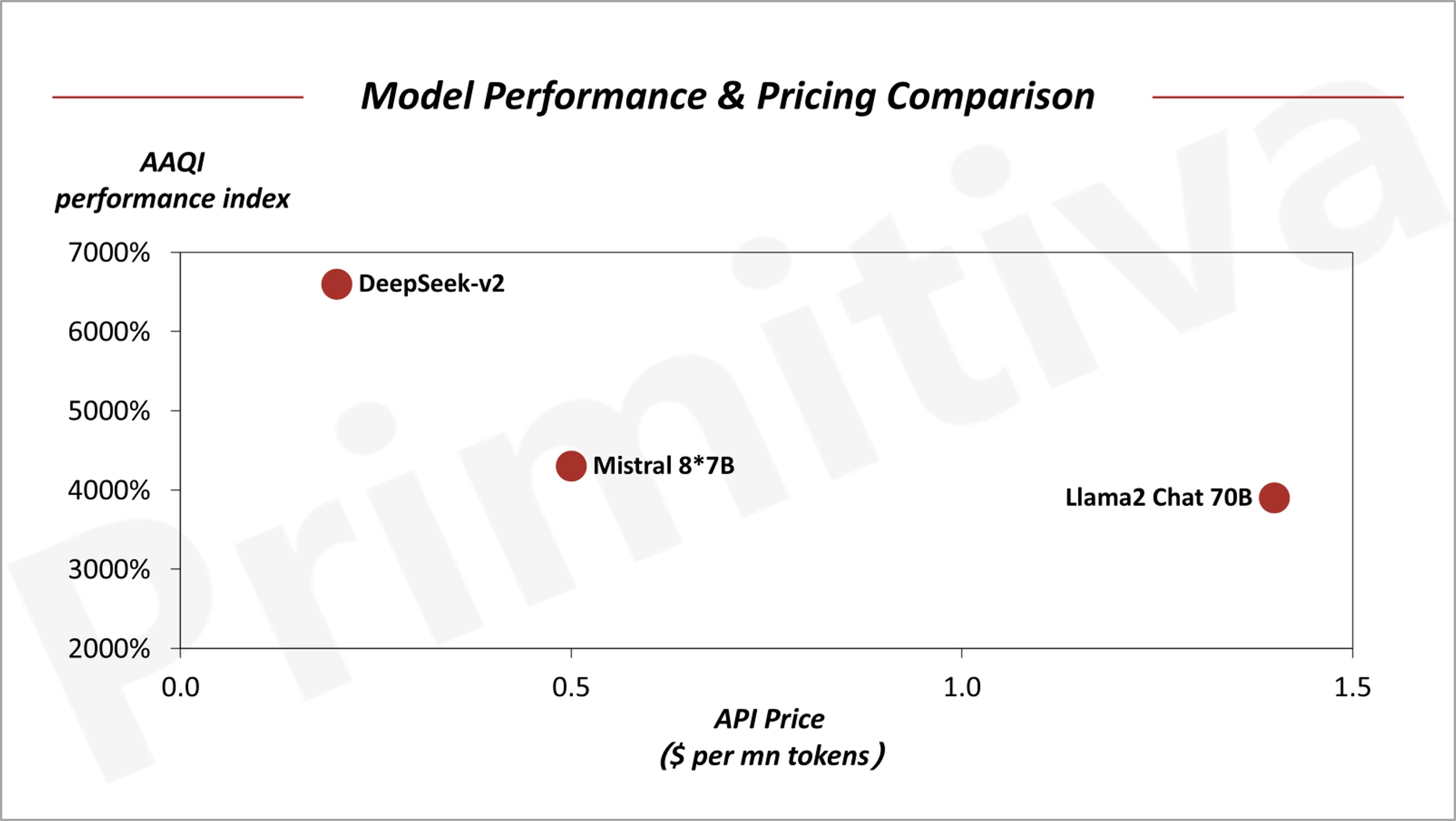
For example, the Mistral 8*7B model employs Sliding Window Attention, Continuous Batching, and the MoE approach to achieve Llama2 70B-level performance at just 35% of the inference cost. Similarly, DeepSeek-V2 has refined its MoE mechanism and incorporated the more advanced MLA attention mechanism, cutting inference costs by an additional 50%.
Hardware Breakthroughs Will Become the New Driver for Reducing Inference Costs
While system and model-level innovations have been the primary drivers of inference cost reductions over the past two years, hardware advancements are now emerging as a critical force in lowering costs further.
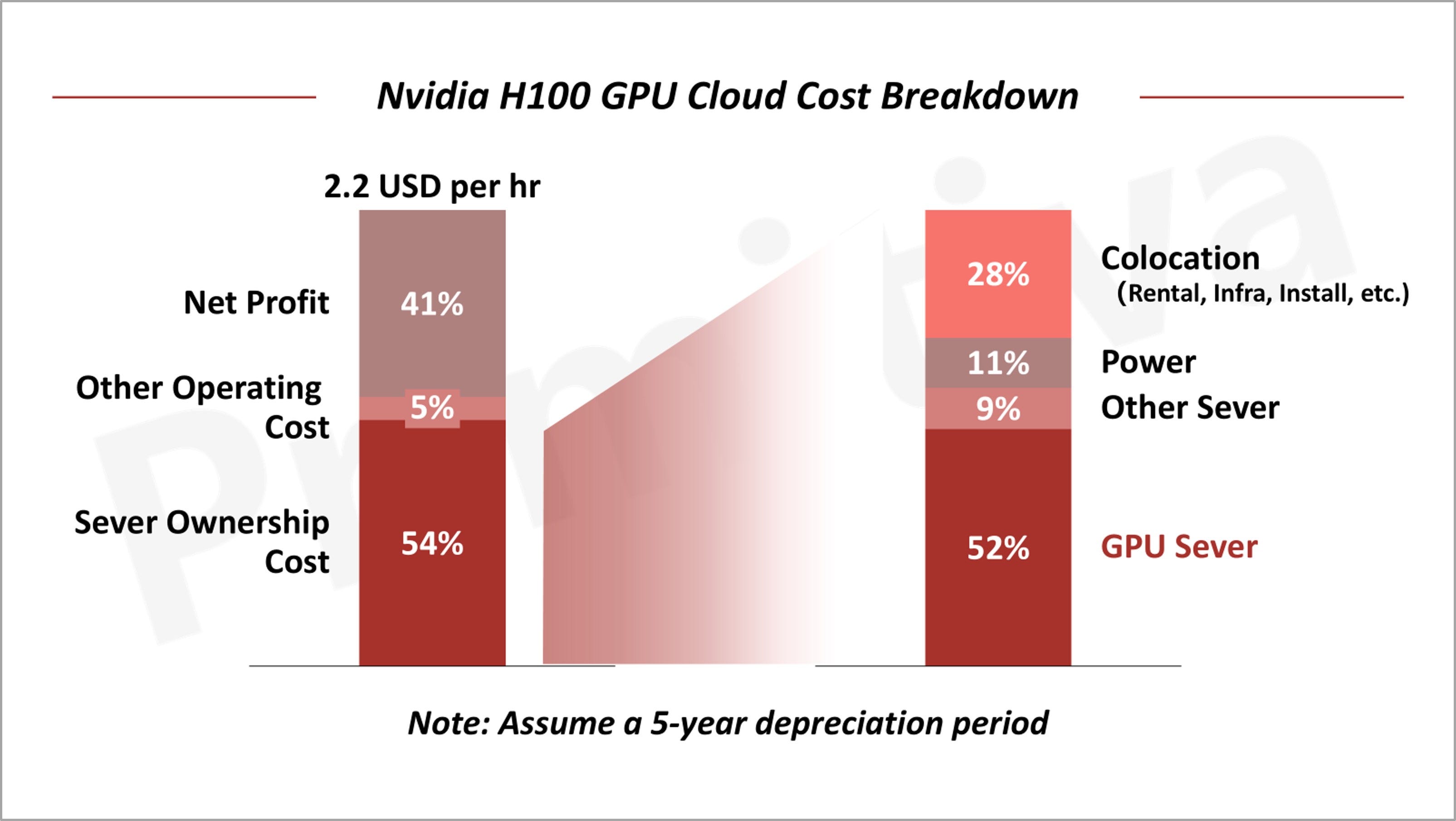
Currently, for every dollar spent on GPU cloud services, 54% goes toward server hosting costs, with GPU purchase expenses accounting for a substantial portion—far exceeding power and other server-related costs. As such, GPU pricing has become a pivotal factor in determining overall inference expenses
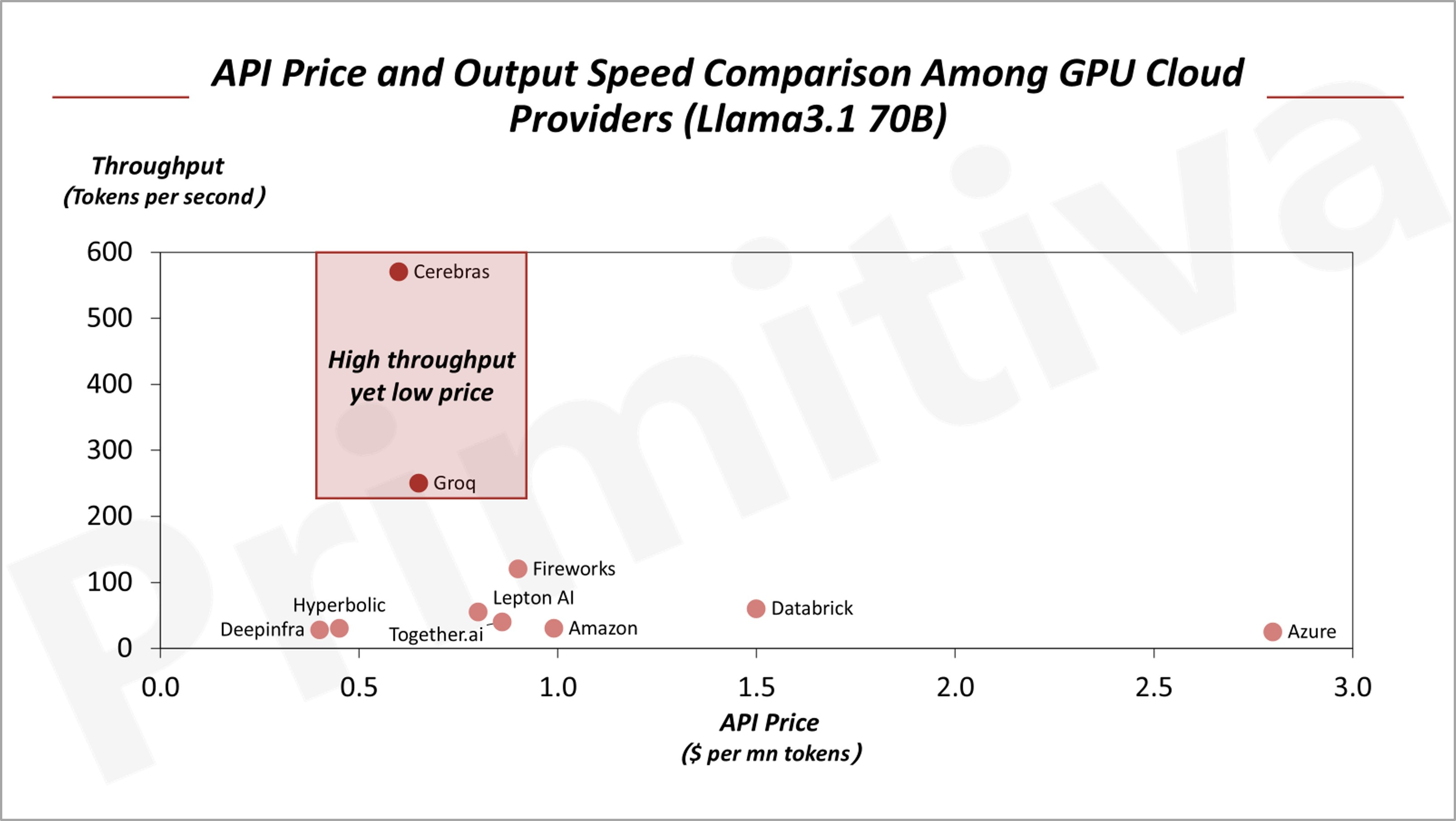
Startups like Groq and Cerebras are addressing GPU bandwidth limitations, significantly enhancing inference efficiency and cost-effectiveness. For instance, when running the same Llama3.1 70B model, API prices from Cerebras and Groq are 30–40% lower than those based on NVIDIA’s H100 GPUs, while also offering faster output speeds.
NVIDIA’s upcoming B200 GPU, expected to debut next year, promises further breakthroughs. According to MLPerf test results, the B200 delivers 4x the throughput of the H100 using FP4 and FP8 precision. Despite an estimated price of $35,000—40% higher than the H100—the B200 is projected to reduce inference costs by approximately 70%. Even at the same precision, cost reductions are expected to range between 30–40%.
The convergence of advancements in GPU hardware with ongoing innovations at the model and system levels is anticipated to drive continued reductions in inference costs, unlocking greater scalability and potential for GenAI applications.
Investment Window is NOW
Beyond cost concerns, GenAI applications face another significant bottleneck: user experience and performance. Historically, transformative technologies have never been just about tech. Yes, the technical breakthrough is the foundation and a necessary condition for a groundbreaking product, yet it is not a sufficient condition as each new tech platform calls for an upgrade in user interface.
The desktop revolution took off with the combination of the mouse and Windows interface, while the rise of short-form video platforms like TikTok and Kwai only went viral with its swipe-up interaction. It took years since the maturity of mobile technologies, including video compression, real-time streaming, 4G mobile networks, smartphone hardware, and recommendation algorithms, before such a new way of interacting with the smart phone got discovered and went viral like the case of TikTok.
Similarly, we believe GenAI as a new technology platform is poised to spark entirely new modes of human-computer interaction. However, these new UI standards may take several years to fully emerge.
Does it mean it is too early to invest? History underscores a critical insight: when industry solutions still exhibit performance gaps, it’s often the ideal time for Series B investments. For Series A and seed rounds, positioning 3 to 5 years ahead of market readiness is essential.
We derived this hypothesis by analysing the Human performance benchmark index, a widely used metric for evaluating measures AI performance relative to human ability, and compare investment performance along each developmental stage along the index.
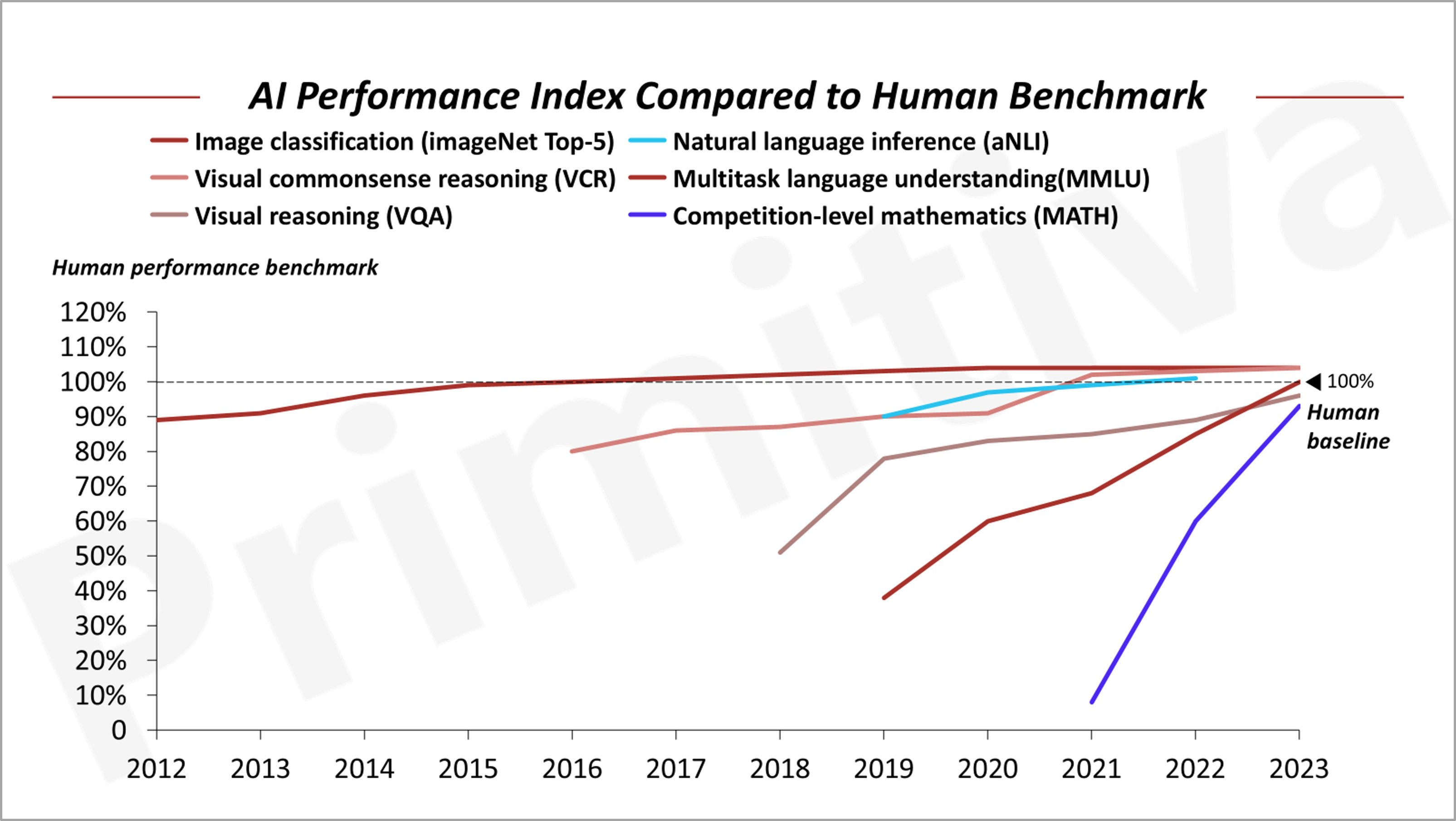
By 2016, visual AI solutions had reached 80% of human capability, enabling early applications in specific domains despite notable limitations. Between 2014 and 2019, the U.S. market witnessed a surge of early-stage investments in visual AI technologies, with graduation rates (to the next round) for seed, Series A, and Series B rounds consistently high at 70–80%. However, by 2019, as visual AI approached perfection and optimization potential narrowed, investment interest began to wane
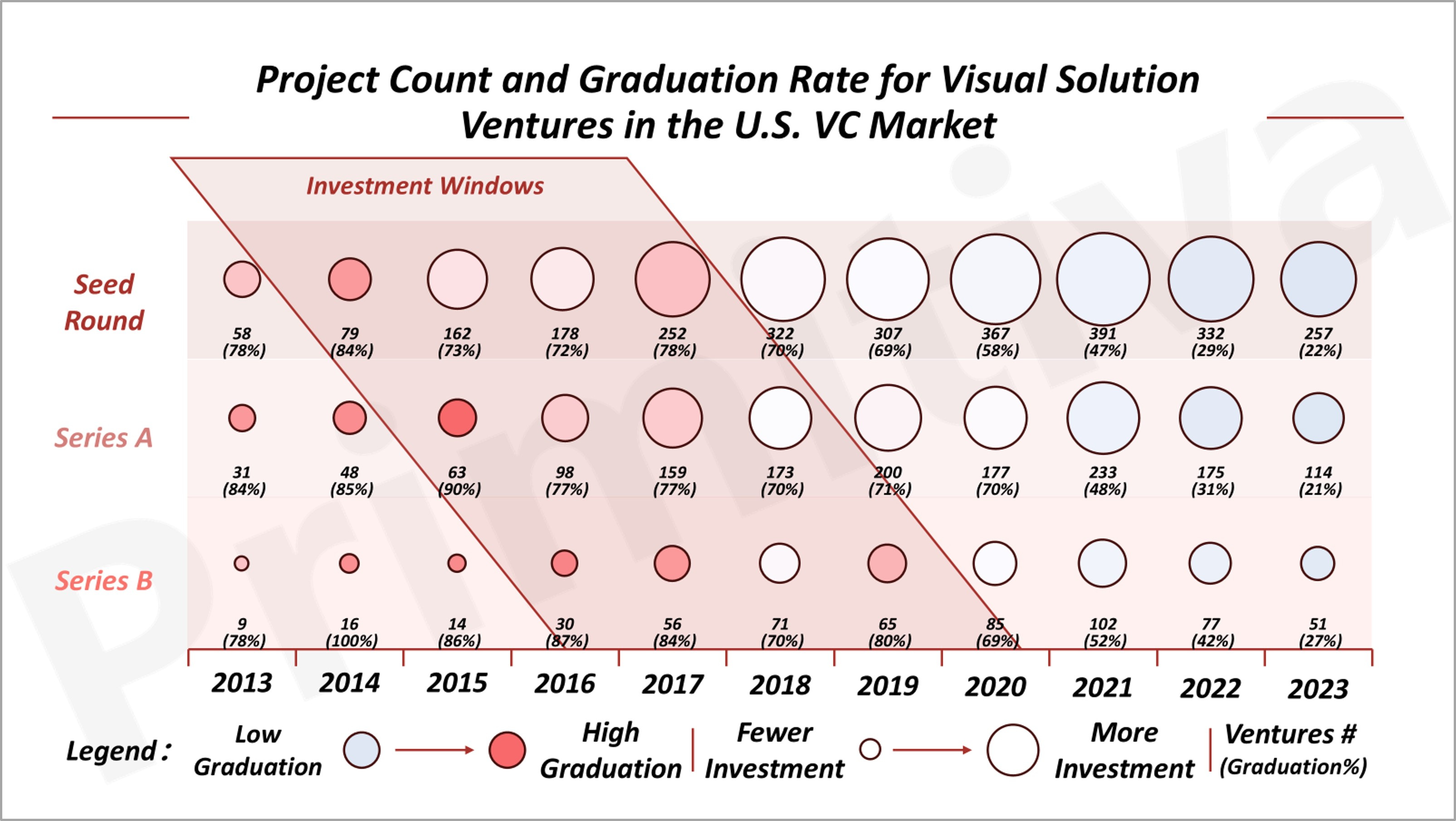
Today, GenAI applications face similar high costs and performance limitations, preventing them from achieving widespread adoption. However, once a product reaches perfection, the prime window for investment may have already closed. It’s precisely these imperfections—cost hurdles, performance gaps, and scalability challenges—that create unique opportunities for early-stage venture investments. By supporting GenAI applications as they overcome these barriers, investors position themselves for outsized returns that are distinct to this critical growth phase.
Special thanks to Jenny Xiao from Leonis Capital for introducing the Human Performance Benchmark Index.
Special thanks to PaleBlueDot.AI for providing valuable feedback and sharing critical insights into the GPU supply and demand market.

PaleBlueDot.AI is a premier marketplace for AI Cloud, bridging the gap between suppliers and consumers of AI Cloud resources. We streamline AI Cloud transactions and offer comprehensive financing solutions to support both sides of this dynamic ecosystem. By harnessing our vast computational power resources, we empower the next generation of Gen AI startups.
Reference:
GPU instance pricing and ROI: What do we know and what can it tell us about supply and demand, Morgan Stanley Research;
What’s next in AI? A framework for thinking about inference compute, Barclays Research;
2024 Spending benchmarks for private B2B SaaS companies, SaaS Capital;
Nvidia Blackwell Perf TCO Analysis – B100 vs B200 vs GB200NVL72, SemiAnalysis;